 |
The OWL Services Coalition1
The Semantic Web should enable greater access not only to content but also to services on the Web. Users and software agents should be able to discover, invoke, compose, and monitor Web resources offering particular services and having particular properties. As part of the DARPA Agent Markup Language program, we are developing an ontology of services, called OWL-S (formerly DAML-S), that makes these functionalities possible. In this white paper we describe the overall structure of the ontology and its three main parts: the service profile for advertising and discovering services; the process model, which gives a detailed description of a service's operation; and the grounding, which provides details on how to interoperate with a service, via messages. We also discuss the motivation for OWL-S, and work on related ontologies for resources and for time.
This white paper accompanies OWL-S version 1.0, which is available at
http://www.daml.org/services/.
Efforts toward the creation of the Semantic Web are gaining momentum [1]. Soon it will be possible to access Web resources by content rather than just by keywords. A significant force in this movement is the development of a new generation of Web markup languages such as OWL[12] and its predecessor DAML+OIL [7,8]. These languages enable the creation of ontologies for any domain and the instantiation of these ontologies in the description of specific Web sites.
Among the most important Web resources are those that provide services. By ``service'' we mean Web sites that do not merely provide static information but allow one to effect some action or change in the world, such as the sale of a product or the control of a physical device. The Semantic Web should enable users to locate, select, employ, compose, and monitor Web-based services automatically.
To make use of a Web service, a software agent needs a computer-interpretable description of the service, and the means by which it is accessed. An important goal for Semantic Web markup languages, then, is to establish a framework within which these descriptions are made and shared. Web sites should be able to employ a set of basic classes and properties for declaring and describing services, and the ontology structuring mechanisms of OWL provide the appropriate framework within which to do this.
This paper describes a collaborative effort by researchers at several organizations to define just such an ontology. We call this language OWL-S2. We first motivate our effort with some sample tasks. In the central part of the paper we describe the upper ontology for services that we have developed, including its subontologies for profiles, processes, and groundings. The ontology is still evolving, and making connections to other development efforts, such as those building ontologies of time and resources.
This paper accompanies OWL-S version 1.0, which is available at [3]. Please note that, in addition to the OWL ontology files, the release site includes examples and additional forms of documentation, including, in particular, a code walk-through illustrative of many points in this document, additional explanatory material (in HTML) regarding the grounding and the use of profile-based class hierarchies, and information about the status of this work, including unresolved issues and future directions.
Services can be simple, or ``primitive,'' in the sense that they invoke only a single Web-accessible computer program, sensor, or device that does not rely upon another Web service, and there is no ongoing interaction between the user and the service, beyond a simple response. For example, a service that returns a postal code or the longitude and latitude when given an address would be in this category. Alternately, services can be complex, composed of multiple primitive services, often requiring an interaction or conversation between the user and the services, so that the user can make choices and provide information conditionally. One's interaction with www.amazon.com to buy a book is like this; the user searches for books by various criteria, perhaps reads reviews, may or may not decide to buy, and gives credit card and mailing information. OWL-S is meant to support both categories of services, but complex services have provided the primary motivations for the features of the language. The following four task types will give the reader an idea of the kinds of tasks we expect OWL-S to enable [13,14].
Any Web-accessible program/sensor/device that is declared as a service will be regarded as a service. OWL-S does not preclude declaring simple, static Web pages to be services. But our primary motivation in defining OWL-S has been to support more complex tasks of the kinds described above.
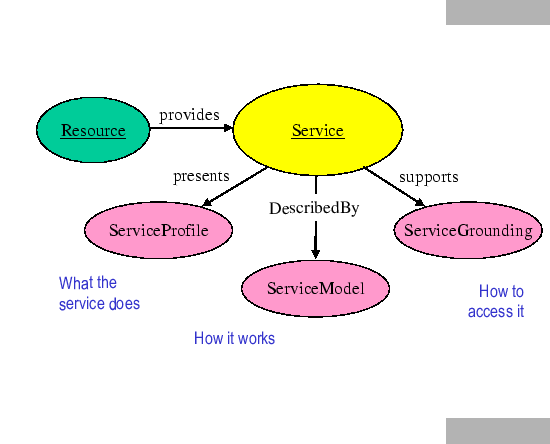
Our structuring of the ontology of services is motivated by the need to provide three essential types of knowledge about a service (shown in figure 1), each characterized by the question it answers:
The class SERVICE provides an organizational point of reference for declaring Web services; one instance of SERVICE will exist for each distinct published service. The properties presents, describedBy, and supports are properties of SERVICE. The classes SERVICEPROFILE, SERVICEMODEL, and SERVICEGROUNDING are the respective ranges of those properties. Each instance of SERVICE will present a descendant class of SERVICEPROFILE, be describedBy a descendant class of SERVICEMODEL, and support a descendant class of SERVICEGROUNDING. The details of profiles, models, and groundings may vary widely from one type of service to another--that is, from one descendant class of SERVICE to another. But each of these three classes provides an essential type of information about the service, as characterized in the rest of the paper.
The service profile tells ``what the service does''; that is, it gives the types of information needed by a service-seeking agent (or matchmaking agent acting on behalf of a service-seeking agent) to determine whether the service meets its needs. In addition to representing the capabilities of a service, the profile can be used to express the needs of the service-seeking agent, so that a matchmaker has a convenient dual-purpose representation upon which to base its operations.
The service model tells ``how the service works''; that is, it describes what happens when the service is carried out. For nontrivial services (those composed of several steps over time), this description may be used by a service-seeking agent in at least four different ways: (1) to perform a more in-depth analysis of whether the service meets its needs; (2) to compose service descriptions from multiple services to perform a specific task; (3) during the course of the service enactment, to coordinate the activities of the different participants; and (4) to monitor the execution of the service.
A service grounding (``grounding'' for short) specifies the details of how an agent can access a service. Typically a grounding will specify a communication protocol, message formats, and other service-specific details such as port numbers used in contacting the service. In addition, the grounding must specify, for each abstract type specified in the SERVICEMODEL, an unambiguous way of exchanging data elements of that type with the service (that is, the serialization techniques employed).
Generally speaking, the SERVICEPROFILE provides the information needed for an agent to discover a service. Taken together, the SERVICEMODEL and SERVICEGROUNDING objects associated with a service provide enough information for an agent to make use of a service.
The upper ontology for services specifies only two cardinality constraints: a service can be described by at most one service model, and a grounding must be associated with exactly one service. The upper ontology deliberately does not specify any minimum cardinality for the properties presents or describedBy. (Although, in principle, a service needs all three properties to be fully characterized, it is easy to imagine situations in which a partial characterization could be useful.) Nor does the upper ontology specify any maximum cardinality for presents or supports. (It will be extremely useful for some services to offer multiple profiles and/or multiple groundings.)
Finally, it must be noted that while we define one particular upper ontology for profiles, one for service models, and one for groundings, nevertheless OWL-S allows for the construction of alternative approaches in each case. Our intent here is not to prescribe a single approach in each of the three areas, but rather to provide default approaches that will be useful for the majority of cases. In the following three sections we discuss the resulting service profile, service model, and service grounding in greater detail.
A transaction in a web services marketplace involves three parties: the service requesters, the service provider, and infrastructure components [21,22]. The service requester, which may broadly identify with the buyer, seeks a service to complete its work; the service provider, which can be broadly identified with the seller, provides a service sought by the requester. In an open environment such as the Internet, the requester may not know ahead of time of the existence of the provider, so the requester relies on infrastructure components that act like registries to find the appropriate provider. For instance, a requester may need a news service that reports stock quotes with no delay with respect to the market. The role of the registries is to match the request with the offers of service providers to identify which of them is the best match. Within the OWL-S framework, the Service Profile provides a way to describe the services offered by the providers, and the services needed by the requesters.
The Service Profile does not mandate any representation of services; rather, using the OWL subclassing it is possible to create specialized representations of services that can be used as service profiles. OWL-S provides one possible representation through the class Profile. An OWL-S Profile describes a service as a function of three basic types of information: what organization provides the service, what function the service computes, and a host of features that specify characteristics of the service. The three pieces of information are reviewed in order below.
The provider information consists of contact information that refers to the entity that provides the service. For instance, contact information may refer to the maintenance operator that is responsible for running the service, or to a customer representative that may provide additional information about the service.
The functional description of the service is expressed in terms of the transformation produced by the service. Specifically, it specifices the inputs required by the service and the outputs generated; furthermore, since a service may require external conditions to be satisfied, and it has the effect of changing such conditions, the profile describes the preconditions required by the service and the expected effects that result from the execution of the service. For example, a selling service may require as a precondition a valid credit card and as input the credit card number and expiration date. As output it generates a receipt, and as effect the card is charged.
Finally, the profile allows the description of a host of properties that are used to describe features of the service. The first type of information specifies the category of a given service, for example, the category of the service within the UNSPSC classification system. The second type of information is quality rating of the service: some services may be very good, reliable, and quick to respond; others may be unreliable, sluggish, or even malevolent. Before using a service, a requester may want to check what kind of service it is dealing with; therefore, a service may want to publish its rating within a specified rating system, to showcase the quality of service it provides. It is up to the service requester to use this information, to verify that it is indeed correct, and to decide what to do with it. The last type of information is an unbounded list of service parameters that can contain any type of information. The OWL-S Profile provides a mechanism for representing such parameters; which might include parameters that provide an estimate of the max response time, to the geographic availability of a service.
The Profile of a service provides a concise description of the service to a registry, but once the service has been selected the Profile is useless; rather, the client will use the Process Model to control the interaction with the service. Although the Profile and the Process Model play different roles during the transaction between Web services, they are two different representations of the same service, so it is natural to expect that the input, output, precondition, and effects (hereafter IOPEs) of one are reflected in the IOPEs of the other.
OWL-S does not dictate any constraint between Profiles and Process Models, so the two descriptions may be inconsistent without affecting the validity of the OWL expression. Still, if the Profile represents a service that is not consistent with the service represented in the Process Model, the interaction will break at some point. As an extreme example, imagine a service that advertises as a travel agent, but adopts the process model of a book selling agent; it will be selected to reserve travels, but it will fail to do that, asking instead for book titles and ISBN numbers. On the other side, it will never be selected by services that want to buy books, so it will never sell a book either.
The selection of the IOPEs to specify in the Profile is quite a tricky process. It should avoid misrepresentation of the service, so ideally it would require all the IOPEs used in the Process Model. On the other side, some of those IOPEs may be so general that they do not describe the service. Another thing to consider is the registry's algorithm for matching requests with providers. Furthermore, the Profile implicitly specifies the intended purpose of the service: it advertises those functionalities that the service wants to provide, while it may hide (not declare publicly) other functionalities. As an example, consider a book-selling service that may involve two functionalities: the first one allows other services to browse its site to find books of interest, and the second one allows users to buy the books they found. The book seller has the choice of advertising just the book-buying functionality or both the browsing functionality and the buying functionality. In the latter case, the service makes public the fact that it can provide browsing services, and it allows everybody to browse its registry without buying a book. In contrast, by advertising only the book-selling functionality, but not the browsing, the agent discourages browsing by requesters who do not intend to buy. The decision as to which functionalities to advertise determines how the service will be used: a requester who intends to browse but not to buy would select a service that advertises both buying and browsing capabilities, but not one that advertises buying only.
In the description so far, we tacitly assumed a registry model in which service capabilities are advertised, and then matched against requests of service. This is the model adopted by registries like UDDI. While this is the most likely model to be adopted by Web services, other forms of registry are also possible. For example, when the demand for a service is higher than the supply, then advertising needs for service is more efficient then advertising offered services since a provider can select the next request as soon as it is free; furthermore, in a pure P2P architecture there would be no registry at all. Indeed the types of registry may vary widely and as many as 28 different types have been identified [22,4]. By using a declarative representation of Web services, the service profile is not committed to any form of registry, but it can be used in all of them. Since the service profile represents both offers of services and needs of services, then it can be used in a reverse registry that records needs and queries on offers. Indeed, the Service Profile can be used in all 28 types of registry.
In the following we describe in detail the main parts of the profile model; we classify them into four sections: the first one (4.2.1) describes the properties that link the Service Profile class with the Service class and Process Model class; the second section (4.2.2) describes the form of contact information and the Description of the profile -- this is information usually intended for human consumption; in the third section (4.2.3), we discuss the functional representation in terms of IOPEs; finally, in the last section (4.2.4), we describe the attributes of the Profile.
The class ServiceProfile provides a superclass of every type of high-level description of the service. ServiceProfile does not mandate any representation of services, but it mandates the basic information to link any instance of profile with an instance of service.
There is a two-way relation between a service and a profile, so that a service can be related to a profile and a profile to a service. These relations are expressed by the properties presents and presentedBy.
Some properties of the profile provide human-readable information that is unlikely to be automatically processed. These properties include serviceName, textDescription and contactInformation. A profile may have at most one service name and text description, but as many items of contact information as the provider wants to offer.
An essential component of the profile is the specification of what functionality the service provides and the specification of the conditions that must be satisfied for a successful result. In addition, the profile specifies what conditions result from the service, including the expected and unexpected results of the service activity. The OWL-S Profile represents two aspects of the functionality of the service: the information transformation (represented by inputs and outputs) and the state change produced by the execution of the service (represented by preconditions and effects). For example, to complete the sale, a book-selling service requires as input a credit card number and expiration date, but also the precondition that the credit card actually exists and is not overdrawn. The result of the sale is the output of a receipt that confirms the proper execution of the transaction, and as effect the transfer of ownership and the physical transfer of the book from the the warehouse of the seller to the address of the buyer.
The Profile ontology does not provide a schema to describe IOPE instances. However, such a schema exists in the Process ontology, as discussed in the next section. Ideally, we envision that the IOPE's published by the Profile are a subset of those published by the Process. Therefore, the Process part of a description will create all the IOPE instances and the Profile instance can simply point to these instances. In this case a single instance is created for any IOPE, unlike in previous versions of OWL-S when, for a certain IOPE, an instance was created both in the Profile and Process part of the OWL-S description. However, if the IOPE's of the Profile are different from those of the Process, the Profile can still create its own IOPE instances using the schema offered by the Process ontology.
The Profile ontology defines the following properties of the Profile class for pointing to IOPE's:
In the previous section we introduced the functional description of services, but there are other aspects of services of which users should be aware. These additional attributes include the quality guarantees that are provided by the service, possible classification of the service, and additional parameters that the service may want to specify.
ServiceCategory describes categories of services on the bases of some classification that may be outside OWL-S and possibly outside OWL. In the latter case, they may require some specialized reasoner if any inference has to be done with it.
To give a detailed perspective on how a service operates, it can be viewed as a process.4 Specifically, OWL-S 1.0 defines a subclass of SERVICEMODEL, the PROCESSMODEL, which draws upon well-established work in a variety of fields, including work in AI on standardizations of planning languages [6], work in programming languages and distributed systems [16,15], emerging standards in process modeling and workflow technology such as the NIST's Process Specification Language (PSL) [19] and the Workflow Management Coalition effort (http://www.aiim.org/wfmc), work on modeling verb semantics and event structure [17], previous work on action-inspired Web service markup [14], work in AI on modeling complex actions [9], and work in agent communication languages [11,5].
The primary kind of entity in the Process Ontology is, unsurprisingly, a process. OWL-S 1.0 adopts two views of processes. First, a process produces a data transformation from a set of inputs to a set of outputs. Second, a process produces a transition in the world from one state to another. This transition is described by the preconditions and effects of the process.
A process can have any number of inputs, representing the information that is, under some conditions, required for the execution of the process. It can have any number of outputs, the information that the process provides, conditionally, after its execution. Besides inputs and outputs, another important type of parameter specifies the participants in a process. There can be any number of preconditions, which must all hold in order for the process to be invoked. Finally, the process can have any number of effects. Outputs and effects can have conditions associated with them.
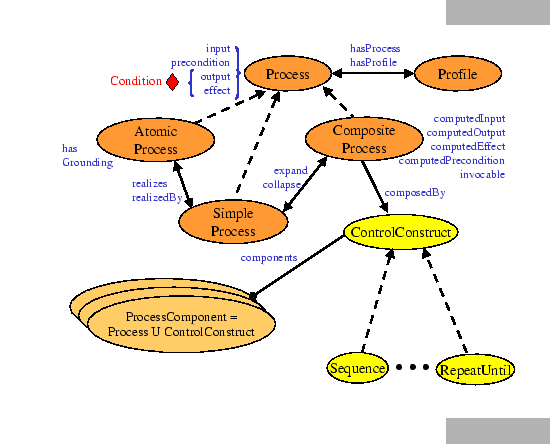
As shown in Figure 2, the process model identifies three types of processes: atomic, simple, and composite. Each of these is described below.
Class PROCESS collects the three types of processes: Atomic, Composite and Simple.
<owl:Class rdf:ID="Process">
<rdfs:comment> The most general class of processes </rdfs:comment>
<owl:disjointUnionOf rdf:parseType="Collection">
<owl:Class rdf:about="#AtomicProcess"/>
<owl:Class rdf:about="#SimpleProcess"/>
<owl:Class rdf:about="#CompositeProcess"/>
</owl:disjointUnionOf>
</owl:Class>
Class PROCESS has related properties hasParameter, hasInput, hasOutput, hasPrecondition, and hasEffect, which range over classes Parameter, Input, ConditionalOutput, Precondition, and ConditionalEffect, respectively. We discuss these properties and classes in the following.
Inputs and outputs specify the data transformation produced by the process. Inputs specify the information that the process requires for its execution. They are similar, in most respects, to arguments of functions in programming languages. The result of the execution of the process is the generation of a set of outputs. Depending on the specification of the Grounding for the process and on the data-flow of the process model, the inputs are either provided by other processes in the process model or by Web service clients through message passing. Equivalently, the outputs are either sent to other processes through the data-flow constructs, or to other Web services.
The following example shows the definition of hasParameter, and its subproperty hasInput:
<owl:ObjectProperty rdf:ID="hasParameter"> <rdfs:domain rdf:resource="#Process"/> <rdfs:range rdf:resource="#Parameter"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasInput"> <rdfs:subPropertyOf rdf:resource="#hasParameter"/> <rdfs:range rdf:resource="#Input"/> </owl:ObjectProperty>
where Parameter, and its subclass Input are used to describe the input types. Outputs are handled similarly, using the ConditionalOutput subclass of Parameter.
The execution of a process may also result in changes of the state of the world. The canonical example is the process that charges a credit card. As a result of the execution of the process, a credit card is charged and the money in the account reduced. Note that there is a fundamental difference between effects and outputs. Effects describe conditions in the world, while outputs describe information. In the context of the example, the service may send a notification, or an invoice, that it charged the credit card account. This output is just a piece of information that some event happened. The effect describes the actual event: that the amount of money in the credit card account has been reduced.
Preconditions specify conditions that should be satisfied for a process to execute correctly. Examples of preconditions are that a credit card should be valid, or that it should not be overdrawn, and so forth.
OWL-S does not assume that outputs and effects are the same for every execution of the process. Rather, it allows the specification of the set of conditions under which the outputs or the effects may result. For example, the credit card may be charged if it is not overdrawn and if the Web service is able to connect with the Credit Card company.
Because of the need for conditions, OWL-S 1.0 defines the classes of ConditionalOuput and ConditionalEffect. Both classes allow a number of conditions to be associated with the outputs and the effects respectively. Unconditional outputs and effects are defined by leaving the list of conditions empty implicitly saying that the condition is always true.
Conditions have a pervasive presence in OWL-S. They are used to describe outputs and effects that result from the execution of processes. They are also used in the specification of constructs such as if-statements and loops (see below).
OWL-S 1.0 does not mandate any language for expressing conditions at present, leaving to the modeler the task of deciding which rule language to adopt. Nor does OWL-S 1.0 make expressivity claims or mandate a specific kind of logic for the rule language. The two main candidates currently are the Semantic Web Rules Language (SWRL), under development at W3C, and DRS, as described by Drew McDermott in an appendix of the OWL-S 1.0 release [18].
The atomic processes are directly invocable (by passing them the appropriate messages). Atomic processes have no subprocesses, and execute in a single step, from the perspective of the service requester. That is, they take an input message, execute, and then return their output message -- and the service requester has no visibility into the service's execution. For each atomic process, there must be provided a grounding that enables a service requester to construct these messages, as explained in Section 6.
<owl:Class rdf:ID="AtomicProcess"> <owl:subClassOf rdf:resource="#Process"/> </owl:Class>
Simple processes are not invocable and are not associated with a grounding, but, like atomic processes, they are conceived of as having single-step executions. Simple processes are used as elements of abstraction; a simple process may be used either to provide a view of (a specialized way of using) some atomic process, or a simplified representation of some composite process (for purposes of planning and reasoning). In the former case, the simple process is realizedBy the atomic process; in the latter case, the simple process expandsTo the composite process.
<owl:Class rdf:ID="SimpleProcess"> <rdfs:subClassOf rdf:resource="#Process"/> </owl:Class> <rdf:Property rdf:ID="realizedBy"> <rdfs:domain rdf:resource="#SimpleProcess"/> <rdfs:range rdf:resource="#AtomicProcess"/> <owl:inverseOf rdf:resource="#realizes"/> </rdf:Property> <rdf:Property rdf:ID="expandsTo"> <rdfs:domain rdf:resource="#SimpleProcess"/> <rdfs:range rdf:resource="#CompositeProcess"/> <owl:inverseOf rdf:resource="#collapsesTo"/> </rdf:Property>
Composite processes are decomposable into other (non-composite or composite) processes; their decomposition can be specified by using control constructs such as SEQUENCE and IF-THEN-ELSE, which are discussed below. Such a decomposition normally shows, among other things, how the various inputs of the process are accepted by particular subprocesses, and how its various outputs are returned by particular subprocesses.
<owl:Class rdf:ID="CompositeProcess">
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Process"/>
<owl:Restriction owl:cardinality="1">
<owl:onProperty rdf:resource="#composedOf"/>
</owl:Restriction>
</owl:intersectionOf>
</owl:Class>
A process can often be viewed at different levels of granularity, either as a primitive, undecomposable process or as a composite process. These are sometimes referred to as ``black box'' and ``glass box'' views, respectively. Either perspective may be the more useful in some given context. When a composite process is viewed as a black box, a simple process can be used to represent this. In this case, the relationship between the simple and composite is represented using the expandsTo property, and its inverse, the collapsesTo property. The declaration of expandsTo is shown above, with SIMPLEPROCESS.
A COMPOSITEPROCESS must have a composedOf property by which is indicated the control structure of the composite, using a CONTROLCONSTRUCT.
<rdf:Property rdf:ID="composedOf"> <rdfs:domain rdf:resource="#CompositeProcess"/> <rdfs:range rdf:resource="#ControlConstruct"/> </rdf:Property> <owl:Class rdf:ID="ControlConstruct"> </owl:Class>
Each control construct, in turn, is associated with an additional property called components to indicate the ordering and conditional execution of the subprocesses (or control constructs) from which it is composed. For instance, the control construct, SEQUENCE, has a components property that ranges over a PROCESSCOMPONENTLIST (a list whose items are restricted to be PROCESSCOMPONENTs, which are either processes or control constructs).
<rdf:Property rdf:ID="components">
<rdfs:comment>
Holds the specific arrangement of subprocesses.
</rdfs:comment>
<rdfs:domain rdf:resource="#ControlConstruct"/>
</rdf:Property>
<owl:Class rdf:ID="ProcessComponent">
<rdfs:comment>
A ProcessComponent is either a Process or a ControlConstruct.
</rdfs:comment>
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Process"/>
<owl:Class rdf:about="#ControlConstruct"/>
</owl:unionOf>
</owl:Class>
In the process upper ontology, we have included a minimal set of control constructs that can be specialized to describe a variety of Web services. This minimal set consists of Sequence, Split, Split + Join, Choice, Unordered, Condition, If-Then-Else, Iterate, Repeat-While, and Repeat-Until.
<owl:Class rdf:ID="Sequence">
<rdfs:subClassOf rdf:resource="#ControlConstruct"/>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#components"/>
<owl:toClass rdf:resource="#ProcessComponentList"/>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
<owl:Class rdf:ID="Split">
<rdfs:subClassOf rdf:resource="#ControlConstruct"/>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#components"/>
<owl:toClass rdf:resource="#ProcessComponentBag"/>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
Examples:
X = (Sequence a b) Y = (Sequence c d) Z = (Unordered X Y)
Z, then, translates to the following partial ordering:
{(a;b), (c;d)}
where ';' means ``executes before'', and the possible execution sequences (total orders) include
{(a;b;c;d), (a;c;b;d), (a;c;d;b), (a;c;d;b),
(c;d;a;b), (c;a;d;b), (c;a;b;d)}
<rdf:Property rdf:ID="ifCondition"> <rdfs:comment> The if condition of an if-then-else </rdfs:comment> <rdfs:domain rdf:resource="#If-Then-Else"/> <rdfs:range> rdf:resource ="#Condition" </rdfs:range> </rdf:Property> <rdf:Property rdf:ID="then"> <rdfs:domain rdf:resource="#If-Then-Else"/> <rdfs:range rdf:resource="#ProcessComponent"/> </rdf:Property> <rdf:Property rdf:ID="else"> <rdfs:domain rdf:resource="#If-Then-Else"/> <rdfs:range rdf:resource="#ProcessComponent"/> </rdf:Property>
When defining processes using OWL-S, there are many places where different properties of a process, or elements referred to by process properties, should be equated, in the sense that the information denoted by the objects of these properties should be the identical whenever the process is instantiated. A simple example is an atomic process to buy something, where the item to be purchased is referred to by some name or identifier provided as an input to the process, and the various process outputs refer to the same identifier, perhaps as parts of a message saying whether the transaction succeeded or failed. There are many places where this equivalence needs to be stated for the process model to be successfully applied by an agent, including:
In a programming language or in a logic language, we would show how these elements were related using variables. In programming, the variables would be function arguments or local variables. They would be referenced in a function body, to indicate how, for example, an argument of some step was the same as an input to the whole function, and how it came from the output of a previous step.
OWL does not provide for the use of variables, especially when defining related classes in an ontology. There is no way to state in a class definition that one of the class properties is referenced elsewhere by a variable name, and that this indicates that the properties' values will be identical when the structure is instantiated. Using OWL, one can only define the inputs and outputs of processes as properties with range restrictions representing the classes of allowed values, independent of any context.
We have considered many schemes to address this limitation in OWL expressivity, and have, for this release, adopted the following OWL notation. The intent is to capture, purely as a set of process annotations, this critical information about how processes are to be instantiated and information shared between process elements. We have extended our process ontology with the classes and properties used in this notation. The use of this notation in a process definition will enable a specialized OWL-S process reasoner to use this information to determine which properties should have ``the same value'' in any coherent instance of the process being defined.
In this notation, an instance of the class VALUEOF, with properties atProcess and theParameter denotes the object (value) of the specified parameter of the specified process. This style of reference is intended to be used only within the context of a process being annotated using the property sameValues, which relates a process to a collection of VALUEOF objects. The set of referenced ValueOf elements are considered to share the same information, as if their values were represented by a single variable.
The OWL definitions of these properties are as follows:
<!-- Used to annotate a process component by describing which
parameters within that process share values.
The range is a List of ValueOf instances. -->
<rdf:Property rdf:ID="sameValues">
<rdfs:domain rdf:resource="#ProcessComponent"/>
<rdfs:range rdf:resource="&rdf;#List"/>
</rdf:Property>
<owl:Class rdf:ID="ValueOf"/>
<!-- This property indicates the Process having the
referenced parameter -->
<rdf:Property rdf:ID="atProcess">
<rdfs:domain rdf:resource="#ValueOf"/>
<rdfs:range rdf:resource="#Process"/>
</rdf:Property>
<!-- The parameter whose values are
referred to. -->
<rdf:Property rdf:ID="theParameter">
<rdfs:domain rdf:resource="#ValueOf"/>
<rdfs:range rdf:resource="#Parameter"/>
</rdf:Property>
The grounding of a service specifies the details of how to access the service - details having mainly to do with protocol and message formats, serialization, transport, and addressing. A grounding can be thought of as a mapping from an abstract to a concrete specification of those service description elements that are required for interacting with the service - in particular, for our purposes, the inputs and outputs of atomic processes. Note that in OWL-S, both the ServiceProfile and the ServiceModel are thought of as abstract representations; only the ServiceGrounding deals with the concrete level of specification.
OWL-S does not include an abstract construct for explicitly describing messages. Rather, the abstract content of a message is specified, implicitly, by the input or output properties of some atomic process. Thus, atomic processes, in addition to specifying the basic actions from which larger processes are composed, can also be thought of as the communication primitives of an (abstract) process specification.
Concrete messages, however, are specified explicitly in a grounding. The central function of an OWL-S grounding is to show how the (abstract) inputs and outputs of an atomic process are to be realized concretely as messages, which carry those inputs and outputs in some specific transmittable format. Due to the existence of a significant body of work in the area of concrete message specification, which is already well along in terms of industry adoption, we have chosen to make use of the Web Services Description Language (WSDL), a particular specification language proposal with strong industry backing, and which we view as representative of such efforts, in crafting an initial grounding mechanism for OWL-S. As mentioned above, our intent here is not to prescribe the grounding approach to be used with all services, but rather to provide a general, canonical and broadly applicable approach that will be useful for the great majority of cases.
Web Services Description Language (WSDL) ``is an XML format for describing network services as a set of endpoints operating on messages containing either document-oriented or procedure-oriented information. The operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint. Related concrete endpoints are combined into abstract endpoints (services). WSDL is extensible to allow description of endpoints and their messages regardless of what message formats or network protocols are used to communicate'' [2].
It may readily be observed that OWL-S' concept of grounding is generally consistent with WSDL's concept of binding. Indeed, by using the extensibility elements already provided by WSDL, along with one new extensibility element proposed here, it is an easy matter to ground an OWL-S atomic process. Here, we show how this may be done, relying on the WSDL 1.1 specification.
The approach described here allows a service developer, who is going to provide service descriptions for use by potential clients, to take advantage of the complementary strengths of these two specification languages. On the one hand (the abstract side of a service specification), the developer benefits by making use of OWL-S' process model, and the expressiveness of OWL's class typing mechanisms, relative to what XML Schema Definition (XSD) provides. On the other hand (the concrete side), the developer benefits from the opportunity to reuse the extensive work done in WSDL (and related languages such as SOAP), and software support for message exchanges based on these declarations, as defined to date for various protocols and transport mechanisms.
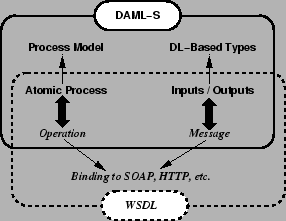
We emphasize that an OWL-S/WSDL grounding involves a complementary use of the two languages, in a way that is in accord with the intentions of the authors of WSDL. Both languages are required for the full specification of a grounding, because the two languages do not cover the same conceptual space. As indicated by Figure 3, the two languages do overlap in the area of providing for the specification of what WSDL calls ``abstract types'', which in turn are used to characterize the inputs and outputs of services. WSDL, by default, specifies abstract types using XML Schema, whereas OWL-S allows for the definition of abstract types as (description logic-based) OWL classes 7. However, WSDL/XSD is unable to express the semantics of an OWL class. Similarly, OWL-S has no means, as currently defined, to express the binding information that WSDL captures. Thus, it is natural that a OWL-S/WSDL grounding uses OWL classes as the abstract types of message parts declared in WSDL, and then relies on WSDL binding constructs to specify the formatting of the messages.
AN OWL-S/WSDL grounding is based upon the following three correspondences between OWL-S and WSDL. Figure 3 shows the first two of these.
Note that OWL-S grounding doesn't mandate a one-to-one correspondence between an atomic process and a single WSDL operation (although that is the most normal case). To accommodate the WSDL-supported practice of providing multiple definitions (within different port types) of the same operation, OWL-S allows for a one-to-many correspondence between an atomic process and multiple WSDL operations. It is also possible, in these situations, to maintain a one-to-one correspondence, by using multiple (differently named) atomic processes.
To construct an OWL-S/WSDL grounding one must first identify, in WSDL, the messages and operations by which an atomic process may be accessed, and then specify correspondences (1) - (3).
Prior to OWL-S version 0.9, correspondences (2) and (3) were required to be direct correspondences. That is, each OWL-S input or output had to directly match up with a particular WSDL message part; and each input/output type had to literally serve as the type specified in WSDL. Starting with version 0.9, this limitation no longer exists. Version 0.9 allows for the specification of XSLT transformations to show how each WSDL input is derived from (one or more) OWL-S input properties, and how each OWL-S output is derived from (one or more) WSDL output message parts.
Although it is not logically necessary to do so, we believe it will be useful to specify these correspondences both in WSDL and in OWL-S. Thus, as indicated in the following, we allow for constructs in both languages for this purpose.
Because OWL-S is an XML-based language, and its atomic process declarations and input and output types already fit nicely with WSDL, it is easy to extend existing WSDL bindings for use with OWL-S, such as the SOAP binding. Here, we indicate briefly how an arbitrary atomic process, specified in OWL-S, can be given a grounding using WSDL and SOAP, with the assumption of HTTP as the chosen transport mechanism.
Grounding OWL-S with WSDL and SOAP involves the construction of a WSDL service description with all the usual parts (types, message, operation, port type, binding, and service constructs).
With respect to the types of the WSDL message parts, it is useful to distinguish two cases: those in which the type is an OWL type (that is, the WSDL service is a ``native speaker'' of that OWL type); and all others. In the first case, the OWL class can either be defined within the WSDL types section, or defined in a separate document and referred to from within the WSDL description, using owl-s-parameter, as explained below -- in which case its definition can be omitted from the WSDL types section.
OWL-S extensions are introduced as follows:
Note that WSDL already allows for the use of arbitrary new attributes in message part elements, and for the use of arbitrary values for the encodingStyle attribute. Thus, extension (3) above is the only point on which a modification to the current WSDL specification 1.1 is called for.
Thus far, we have only shown how WSDL definitions may refer to the corresponding OWL-S declarations. It remains to establish a mechanism by which the relevant WSDL constructs may be referenced in OWL-S. The OWL-S WSDLGROUNDING class, a subclass of Grounding, serves this purpose. Each WSDLGROUNDING instance, in turn, contains a list of WSDLATOMICPROCESSGROUNDING instances.
A WSDLATOMICPROCESSGROUNDING instance refers to specific elements within the WSDL specification, using the following properties:
Additional explanation and examples of how to specify groundings are given in an online document [10].
There is an unresolved issue having to do with OWL-S atomic processes that make use of conditional outputs, that is, that specify two or more possible sets of outputs. Because WSDL 1.1 allows only a single output message specification for a given operation, and because OWL-S' treatment of conditional outputs is expected to evolve further, this issue has been left unresolved in the current release (OWL-S 1.0).
Services are effected by processes and processes generally require resources. Therefore, an ontology of resources is an important component of an ontology of services. Our aim here is to propose an ontology of resources stated at an abstract enough level to cover physical, temporal, computational, and other sorts of resources. Specific kinds of resources will, of course, have specific properties; in this development we sketch out the principal classes of properties a resource might have. The OWL-S file Resource.owl contains a version of the portions of the ontology that can currently be encoded in OWL. As OWL develops, particularly in the area of expressing rules, the various constraints on concepts in the ontology will be written up in OWL as well.
First of all, a distinction must be pointed out. There are resource types, such as fuel. There are resource tokens, such as the fuel in the gas tank of a particular car. And there is the quantity, or capacity, of the resource token at any given instant, such as the five gallons of fuel in the car's tank right now. We are primarily interested in the second of these notions. Resources in this sense can, depending on resource type, be consumed, replenished, locked, and released. A resource token, or simply resource, is what is available to an activity.
Resources are allocated to activities or processes. A principal distinction in types of resources concerns their status after the activity stops using them. We will call this the resource's AllocationType. If a resource is gone after it is used, its AllocationType is ConsumableAllocation. If not, its AllocationType is ReusableAllocation.
Examples of reusable resources are the use of a device, the availability of an agent, the use of a region of space, and the use of bandwidth. (These could be viewed as consumable uses of the cross product of the resource (e.g., space) with time, but they are easily decomposed into the resource and time, where only time is consumed.) A persistent resource can be locked and released. When it is locked, it cannot be used by another agent.
Examples of consumable resources are food, charge in a battery, fuel, money, and time. Consumable resources can sometimes be replenished after they are consumed. A deadline is an indirect constraint on the consumable resource of time.
Many resources, such as food, are perishable. We can view this case as having two processes operating on the resource - one functional and relatively rapid, one dysfunctional and relatively slow. Thus, eating food is functional, food spoiling is dysfunctional, and eating is rapid relative to spoiling.
Preconditions on processes can often be viewed as the availability of some resource. Many processes have a location precondition or, more generally, an access precondition. Permission would be an example. In general, if a process is executed as a precondition to another process, we can view its product (or its having been done) as a resource. Something being in the right location for a process's execution can thus be seen as a resource.
Resources generally have a precise quantitative measure of capacity at any given instant of time. (Enthusiasm is an interesting limiting case - it is a consumable resource that can be replenished and is required for many tasks, but it cannot be measured precisely. Attention is a similar resource.)
The quantitative measure might be continuous, such as the quantity of fuel. Or it could be a discrete measure, such as a number of chairs occupied. Thus, a resource has a CapacityType, where the two CapacityTypes are DiscreteCapacity and ContinuousCapacity.
Capacity can be related to various other resource-theoretic predicates. In the following rules, for future incorporation into the OWL ontology, R stands for a resource, A for an activity, T for a time interval, and t for a time instant. The expression use(A,R,T/t) means that activity A uses resource R over time interval T or for time instant t. The expression capacity(R,T/t) refers to the capacity of resource R over time interval T or for time instant t.
The capacity of a persistent resource at the beginning of its use is the same as at the end.
The quantity of a consumable resource at the beginning of its use is more than at the end.
When an agent replenishes a resource during period T, there is more after the replenishment.
When a reusable resource is used for period T, it is locked at the beginning of T and released at the end.
Capacities of resources can also have a capacityGranularity, that is, the units in terms of which the capacity is measured.
A resource can be atomic, or it can be an aggregate. Thus, AtomicResource and AggregateResource are subclasses of Resource.
Some atomic resources can be shared by different activities, while others cannot. For example, several activities may need a table but can in fact use the same table. We thus distinguish between unit capacity atomic resources, whose availability to an activity is a yes-no question, and batch capacity atomic resources, which can support multiple activities in a synchronized fashion. UnitCapacityResource and BatchCapacityResource are subclasses of AtomicResource.
Aggregates can be conjunctive or disjunctive. For conjunctive aggregates, all the elements must be allocated to the activity. For a disjunctive aggregate a subset of the elements in the aggregate can be allocated. An example of a disjunctive resource is a process that requires any 3 adjacent chairs of 100 chairs in a room. Thus, ConjunctiveAggregateResource and DisjunctiveAggregateResource are subclasses of AggregateResource.
Shareable resources should be understood in terms of batch capacity resources and aggregation.
A very important use of an ontology of resources could be in a monotonic version of ``negation as failure'' in a rules language. In this view, ``not P'' would not be negation as failure. Rather one would use the predicate ``cantfind(P,R)'' where R is some indication of the resources to devote to the search for a proof of P. For example, R could then be a list or description of Web resources, a certain number of inference steps, or a certain amount of time.
OWL-S is an ontology, within the OWL-based framework of the Semantic Web, for describing Web services. It will enable users and software agents to automatically discover, invoke, compose, and monitor Web resources offering services, under specified constraints.
This technical overview accompanies the release of OWL-S version 1.0. The release materials can be found at http://www.daml.org/services/. A variety of other documents on this site give examples, additional documention, and information about limitations of the current release and future directions in the evolution of the ontology.
We expect to enhance OWL-S in the future in ways that we have indicated in this technical overview and elsewhere, and in response to users' experience with it. We believe it will help make the Semantic Web a place where people can not only find information but also get things done.