Intent of Work
DAML
OnTo-Agents -
Enabling Intelligent Agents on the Web
http://www-db.stanford.edu/ontoagents/
13 April 2001
PI:
Gio Wiederhold, Professor of Computer Science, Stanford University
Subcontractors:
University of Karlsruhe, Germany
Technical Contact:
Stefan Decker, Research Associate
Stanford University, Gates Bldg., Stanford, CA 94305
Phone: (650) 723-1442
Fax: (650) 725-2588
Email: [email protected]
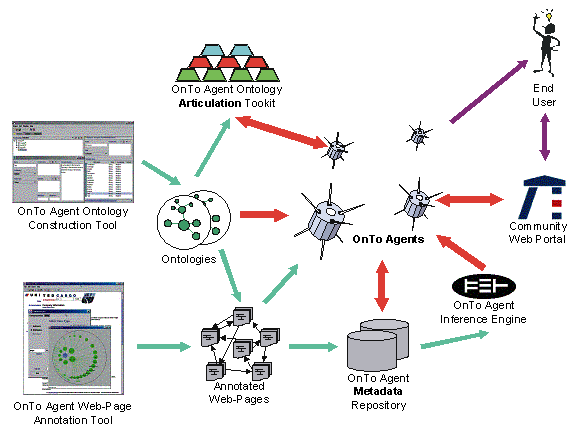
The goal of OnTo-Agents is still to establish an agent infrastructure on the WWW or WWW-like networks. Such an agent infrastructure requires an information food chain every part of the food chain provides information, which enables the existence of the next part. An overview of the OnTo-Agents information food chain is depicted in Figure 1.
Figure 1 OntoAgents Information FoodChain
Specifically, we will make the following contributions:
1. Layered Data Model Integration
2. Repository for aggregating distributed RDF data
3. OntoWebber: A Web Site Management System for SemanticWeb.org
4. Ontology Articulation
5. Inference Engine
6. Annotation Tool
7. OntoAgents Ontology Editor
In addition to the data exchange languages developed in the DAML project, a variety of data models and standards will continue to be deployed both on the Semantic Web, and in DoD and commercial intranets.
Such data models are typically based on object-oriented concepts and include E/R models, UML, XML Schema, RDF Schema. We are developing a technology for enabling interoperation between complex data models and the DAML languages. Our objective is, a.o., to bridge the differences of granularity that these data models will represent. For a data model translation approach to scale to large terminologies, we suggest a layered technique similar to the one used in internetworking. In particular, we plan to accomplish the following goals:
· Configure data models of interest conceptually into model stacks, or sequences of layers.
· Build gateways between representation mechanisms operating/used in the same layer.
· Develop a software architecture for composing gateways for model translation.
· Develop components for parsing source formats like RDF/XML or UML/XMI into internal object models suitable for application of gateway chains.
· Demonstrate the scalability and effectiveness of the approach on the example of interoperation between DAML languages that are being developed and other widely used non-DAML data models.
A promising future work direction for this thrust includes raising the level of abstraction for data interoperation tasks, so that data models, ontologies, and mappings between them can be manipulated as first-class objects in an algebraic fashion. Such approach promises high modularity and streamlining of interoperation solutions.
Building the information food chain for intelligent agents requires processing and managing large amounts of data and metadata. For example, a simple task of determining the title of a book with a given ISBN number requires processing large volumes of data that possibly originate from multiple data sources.
We are building a repository for gathering distributed RDF data from Web pages and other data sources. Our major goal is to help automated agents in locating relevant machine-processable information. In particular, we are working on:
· Building an RDF crawler for collecting DAML/RDF-enabled Web pages (reusing existing crawlers)
· Developing tools for importing data from special-purpose RDF data sources (like Open Directory), and non-RDF, but highly relevant data sources (like WordNet).
· Recrawling data periodically to ensure freshness.
· Offering a search/browsing interface for human users.
· Defining a search interface for automated agents.
· Providing metadata about the origin of crawled data, including the time and date when we acquired the local copy.
Since RDF data has a much finer granularity than text documents, querying of aggregated RDF data is extremely resource-intensive. As future work, we plan to investigate how to provide efficient support for more complex queries, transitive closures, and trust-related issues.
We have set up and established http://SemanticWeb.org as the Semantic Web portal. The next step is to automate the portal as much as possible. The goal of the system is to provide an environment with a set of supporting tools for designing, generating and maintaining data intensive Web Sites. Based on the DAML technology and a model-driven approach, we are able to apply coherent data storage and querying, logic inference, information integration, and hypertext design methodology to the system we are developing, thus largely ease the job of Web site data management.
The intended users of SemanticWeb.org are people interested in Semantic Web resources. The intended user of the Web site data management system are website provider, which need to display, integrate and especially maintain data from different heterogeneous independent sources. Examples include internal Webportals of companies, which provide information from internal as well as external sources in a uniform way.
The services provided by the DAML repository provide an important motivation for accessing this portal.
We are building a tool for generating the articulation between ontologies associated with information sources. Dealing with multiple ontologies is essential to gain information for decisions from multiple sources. Articulation allows linkage of ontologies that come from distinct sources without requiring their complete integration.
For example, the purchasing department of a company needs to make decisions about what equipment to purchase by looking at the company's own needs and the capabilities of its equipment suppliers. But the variety of suppliers will not use identical terminologies, nor structure their catalogs in exactly the same way. Certainly the way that DoD defines their needs will conflict with the rapidly changing commercial world.
A major difficulty in answering non-trivial queries, even when adequate in their databases, is the semantic gap that typically exists between the two information sources (e.g, synonyms, homonyms, partial overlaps). Imprecision, in turn, causes both missed opportunities (type 1 errors) and information overload (type 2 errors). We will focus on type 2 errors since the quantity of information be receive today from queries on the web is such that the end-user cannot afford the time to investigate all potential leads.
We need intelligent, user-friendly, semi-automated tools that assist the end-users to resolve the semantic heterogeneity that exists between the terminology used internally by the company and that used by the suppliers. Similar problems are commonly encountered in logistics, e-commerce, etc.
We are building a framework to articulate ontologies that represent heterogeneous information sources from which we intend to compose information. Specifically, the two major contributions from our project are:
· Design and implement heuristic methods to generate better articulations between ontologies.
· Develop a GUI tool that assists a human expert to validate the automatically generated articulations.
· Establish formally the properties of an ontology algebra.
We also foresee the use of the algebra in optimizing queries by rearranging the operations. Our future work will be:
· to add several more novel heuristics to or library of reusable heuristic articulation algorithms and
· to use the algebra to rewrite queries and optimize query plans.
The effect will be that we can rapidly build, alter, and maintain the semantic bridges that will serve the traffic on the electronic highways.
DAML, as a knowledge representation language, needs a query and inference mechanism. Furthermore it is necessary to combine DAML Ontologies with all kind of other data sources (product catalogs, directories like DMOZ etc.) to allow exploitation of the ontologies in large-scale applications. These different data source often have their own semantics, so that a query and inference mechanism for DAML must also be able to capture other semantic definitions. We have started to implement TRIPLE (see (http://www-db.stanford.edu/~stefan/2001/02/rdfinterest/), an inference engine for the integration of DAML Ontolgies with other data with heterogeneous semantics. TRIPLE supports DAML+OIL as much as possible for horn logic inference engines and also enables information integration of Ontologies and data with various semantics.
Using pure Horn logic as an inference and query mechanism is like writing client-server applications in assembler: possible, but not very convenient and economical. TRIPLE supports RDF data with various semantics, is able to deal with RDF models (subsets of statements) and supports a frame-based view on RDF data. Furthermore rules itself will be available on the web as a data source. Integration of differing rules requires a conflict handling mechanism, since independently developed rules can possibly conflict with each other. To implement the conflict handling mechanism, we are teaming up with Benjamin Grosof, a DAML contractor at MIT. We are jointly adapting the Courteous Logic Programming method for TRIPLE, effectively enabling TRIPLE to process rule sets from various sources.
Since TRIPLE needs an inference core, XSB (see http://xsb.sourceforge.net) is taken to be this inference core. For the bridging of XSB and Java we developed tool support, that realizes a direct XSB and Java connection. Furthermore we have set up a XSB usage page to collect and coordinate all developments efforts going on with XSB within DAML (see http://www.semanticweb.org/XSB/).
Intended users of TRIPLE are information integrators on the Semantic Web, the agents that have to integrate data from various sources. TRIPLE helps them to declaratively specify and compute the semantics of the collected RDF data.
The technical goal is to develop/advancing a user-friendly interactive webpage annotation tool: Ont-O-Mat. Ont-O-Mat supports the user with the task of creating and maintaining ontology-based DAML markups i.e. creating of DAML-instances, attributes and relationships. Ont-O-Mat will include an ontology browser for the exploration of the ontology and instances and a HTML browser that will display the annotated parts of the text.
Ont-O-Mat will be Java-based and provide a plugin interface for extensions. It will be easy to extend the functionality. Third-party developers will be able to use this tool as well.
One of the plugins we will provide is an information extraction component for semi-automatic metadata creation. Ont-O-Mat will offer a wizard that suggests which parts of the text are relevant for annotation. That aspect will help to ease the time-consuming annotation task.
We will collaborate with ISI to build a simple heterogeneous DAML service for the retrieval of available DAML tools and services running at www.semanticweb.org. To initialize this task Karlsruhe will create a “shallow” upper DAML-based Ontology of currently available DAML tools to classify the currently available tools according to that ontology (classifying eg. Ontology Editors, Inference Engines, Annotations Tools, and Matching Tools).
For the collaboration with ISI we will use Ont-O-Mat in two ways. First, we will use Ont-O-Mat to annotate DAML tool description pages and second we will reuse the ontology viewer component to realize a viewing service.
The intended user is the individual annotator i.e., people that want to enrich their web pages with DAML-meta data. Instead of manually annotating the page with a text editor, say, emacs, Ont-O-Mat allows the annotator to highlight relevant parts of the web page and create new instances via drag’n’drop interactions. It supports the meta-data creation phase of the lifecycle.
An alpha version of Ont-O-Mat is now available, which need the last 10% of work, i.e. debugging and polish so we will be able to release a free beta version about May 2001. The first version will not jet contain the information extraction plugin.
The information extraction plugin will need the following steps: information extraction, system evaluation and selection, design of the information extraction framework, formulation of text extraction, annotation heuristics testing, improvement of heuristics evaluation, and dissemination.
Parallel to that we will improve the Onto-O-Mat according to the user feedback.
In the course of the DAML program, we plan to adapt Protégé-2000 to become a full-fledged DAML editor. Exploiting the experience gathered over many years and in many projects with non-computer expert end-users is valuable input and allows us to focus on features found valuable and ignore features that were not effective (eg. graphical representation of ontologies, drag&drop parts of the hierarchy, datatypes etc.). This adaptation includes a representation of all elements of the DAML knowledge model in Protégé-2000, development of user-interface components that facilitate acquisition of DAML ontologies, improving support for handling multiple ontologies (including semi-automated merging and mapping among ontologies), and an implementation of an interface between Protégé-2000 and DAML reasoning services (such as classifiers). We believe that as such, Protégé-2000 will become a comprehensive tool for DAML ontology developers—users who are familiar with knowledge-representation paradigms and that are experts in a specific domain of interest (such as military) but are not necessarily computer-science experts.
The next logical steps in the editor development cycle are:
a. lowering the barrier for ontology-development by employing advanced user-interface and reasoning features that would guide developers through the process of defining a model for a domain, analyze the model to help users fine-tune it, and, acquire elements of the model from existing DAML sources
b. developing a cooperative ontology-editing environment that would enable communities of domain experts to work collectively on developing models for their domains.
We have already participated in a number of conferences and made presentations on our OntoAgents and predecessor activities. For the future we will be engaged in further activities to disseminate DAML-motivated initiatives.
International Semantic Web Workshop, July 30-31, 2001, Stanford, USA
Rationale: The goals of this Workshop are manifold: first of all, there is a strong US and European community working on Semantic Web topics. However, our interaction points are currently very limited. The workshop tries to bring researchers from Europe and USA together to facilitate collaboration facilities.
Furthermore, the W3C Semantic Web initiative needs a test bed – standardization of a technology only makes sense if enough parties have tried various instantiations of the technology and identified weaknesses. The workshop is aiming to be a platform collecting experiences with Semantic Web technology – as a direct input for the (e.g. W3C) standardization processes.
Cooperation Partners are: Stanford KSL, INRIA France, and the Worcester Polytechnic Institute, Boston, USA.
Other activities include
· Working on the relationship between TopicMaps and DAML. TopicMaps is a recent ISO standard and enjoys strong commercial support (see http://www.semanticweb.org/resources.html#commercial for a list of companies supporting TopicMaps). To prevent the Semantic Web from splitting in two separate incompatible sub-webs, it is important to relate DAML to TopicMaps. We, together with Martin Lacher (a visitor from the Technical University of Munich) achieved a first success by developing an RDF model of TopicMaps. Using our InterDataWorking approach and deploying our inference engine TRIPLE, we hope to make DAML and TopicMaps interoperable.
· Dissemination of DAML and Semantic Web Technologies at the Semantic Web Workshop during WWW10 (May 31, Hong Kong). We involved in co-organizing this event, together with the University of Karlsruhe, University of Amsterdam, and the University of Georgia.
This appendix elaborates on the cooperation with ISI (Martin Frank).
1. Create a “shallow” upper ontology of currently available DAML tools (parsers, crawlers, viewers, editors). [Karlsruhe]
2. Classify currently available tools according to that ontology. [all]
3. Create polished WebScripter reports of the available tools. [ISI]
4. Put up this living (self-refreshing) list of DAML tools on semanticweb.org [Stanford DB], support from ISI]
5. Create a dedicated ontology for a Web-based DAML viewer (a servlet that when given a list of URLs will load the DAML and render it to HTML in some fashion) [both Karlsruhe and ISI, independently, separately conceived ontologies, separately written viewing service].
6. Use WebScripter to map each ontology into the semanticweb.org ontology (as a result, the viewing services show up on SemanticWeb.org page) [ISI and Karlruhe]
7. Use WebScripter to produce DAML that asserts the equivalence of invocation parameters of the two viewing services. [ISI]
8. Write a program that takes a DAML database, dynamically discovers available viewers by consulting WebScripter ontology equivalence information, and then actually invokes one of the viewing services. [Karlsruhe and ISI]. This final step presents some first semantic interoperability at the tool level (new viewing services can be discovered and incorporated without having to re-write any code of the invoking program).
DAML establishes the foundation for intelligent agents on the Web: machine understandable information is available for automated agents. One of the remaining questions is how to enable ordinary Internet users to construct their personal Internet agent for specific tasks. If extensive programming knowledge and effort is required to create a personal agent for a specific task, then a real agent based Web will not happen. Instead Internet users have to rely on the services of companies, which construct agents for predefined tasks – not much of an improvement compared to the current situation.
The new necessary infrastructure to enable ordinary users to construct agents will build upon the results of the first DAML phase. We have the following vision for an infrastructure that enables Internet users to construct agents: The Web, as it currently exists, allows to share human readable information. DAML enables the sharing of static knowledge among machines. The next phase is to enable the sharing of dynamic knowledge among machines: Knowledge that describes how tasks on the Web are performed.
For example, the task of booking a cost-effective hotel close to a known meeting point can be decomposed in set of generic, non detailed subtasks (e.g. “Find all hotels”, “determine distance to meeting point”, etc.). Please note that is not necessary to know all the details of the subtasks – they can be instantiated on a case-by-case basis. A set of tasks, together with data and control flow among the tasks, represents a process. Representing processes in a machine understandable way enables Internet users to create and exchange process knowledge.
We expect that these processes solve problems at different levels of detail: e.g. one process realizes the tasks of booking a cost-effective hotel close to a known meeting point. Another process, independently developed, defines a way to find all hotels, etc. A composition and configuration framework for processes enables Internet users to configure several processes at various levels of detail resulting in an executable agent solving a particular problem in a specific way. A major problem is the mediation of information (data) inside such an agent: since the processes at different levels of details were developed independently of each others the information passed around at the different levels of details is usually incompatible (the processes use different ontologies to represent the information processed).
We have already developed the basic framework for representing shareable processes at various levels of details and for configuring and combining processes to executable agents. This includes a process ontology, describing the vocabulary necessary to represent a process, a configuration ontology (the vocabulary necessary to configure and link different processes), and a compiler to compile processes and configuration descriptions to executable Java Code. As major tasks for the outer years we expect the following items:
We believe that especially the last item leads to self-adapting and self-extending intelligent agents.